인공지능, 머신러닝, 딥러닝 차이
- Deep Learning/Tensorflow & Keras
- 2022. 9. 17.
많은 분들이 헷갈려 하시는 것이 있는데 바로 인공지능(Artificial Intelligence)과 머신러닝(Machine Learning) 그리고 딥러닝(Deep Learning)의 차이를 모르시고, 3가지의 구분되는 개념을 동일한 개념으로 이해를 하시는 분들이 많습니다.

인공지능(Artificial Intelligence)
3개의 용어 중 최상위 개념이 바로 인공지능입니다. 최상위라는 말에서 알 수 있듯 머신러닝 혹은 딥러닝은 인공지능 이라는 개념의 하위 용어이기도 합니다. 한마디로 수학으로 따지면 포함한다라는 뜻과 같습니다.
인공지능은 사람들이 느꼈을 때, 마치 지능이 있을 법한 행동을 하는 프로그램을 뜻합니다. 즉 지능을 구현하기 위해서 상당히 많은 노가다성 코딩이 있거나 하여도 사람들이 인공지능이라 느끼면 인공지능이 되는 것이죠. 대표적으로 한 예를 들어보겠습니다.
어떤 사람의 신체를 측정하고, 이 사람의 체격을 기반으로 합격이든 불합격이든 자동으로 계산을 하는 프로그램이 있다고 가정을 해보죠. 이 것을 구현하는 많은 방법이 있겠지만 아래와 같이 매우 간단한 코딩으로도 구현이 됩니다.
boolean isFirst = false;
if(몸무게 < 100 && 몸무게 > 80 && 키 > 180) {
isFirst = true;
}
위와 같이 3가지의 간단한 조건문으로 이 사람의 등급을 계산해서 1등급인지 아닌지를 계산하게 되는데 이것도 인공지능이라 말을 할 수 있습니다. 사용자가 프로그램 내부 코드를 보지 못하기 때문에 인공지능이라 느낀다면 인공지능이라 말을 할 수 있는 것이죠.
혹은 매우 간단한 번역 프로그램을 짜는데 예륻 들어 한자를 한글로 바꿔주는 프로그램이 있다고 해보죠. 그러나 이 프로그램은 사전만 잘 만들어지면 매우 간단하게 짤 수 있습니다. 즉, 매우 심플한 코딩인데 사람들은 인공지능처럼 느껴질 수 있는 것이죠.
이처럼 인공지능이라는 개념은 사람들이 보기에 컴퓨터가 지능을 가지고 있는 것 같다라는 것입니다. 게임을 할때에도 매우 잘 알 수 있는데요. 컴퓨터의 몬스터를 구현하기 위해서 수많은 랜덤 함수 등을 써서 의외성을 만들어내고 행동 패턴을 등록하게 되면 지능이 있는 것처럼 느껴질 수 있는 것이죠.
이처럼 수많은 부분에 인공지능이라는 말을 쓰기 때문에 사실 인공지능이 아닌 분야가 별로 없습니다. 예를 들어, 세탁기에 이상한 부품이 들어와서 감지를 하면, 기업은 "인공지능 시스템"으로 탐지라는 말을 쓰면서, 인공지능 업체라고 홍보를 하게 됩니다. 그래서 최근에는 이렇게 너도나도 인공지능이라는 표현을 쓰지 않아야 된다는 주장이 꽤 제기되고 있고, 강 인공지능, 초 인공지능이라는 용어들도 등장하기 시작하였습니다.
머신러닝(Machine Learning)
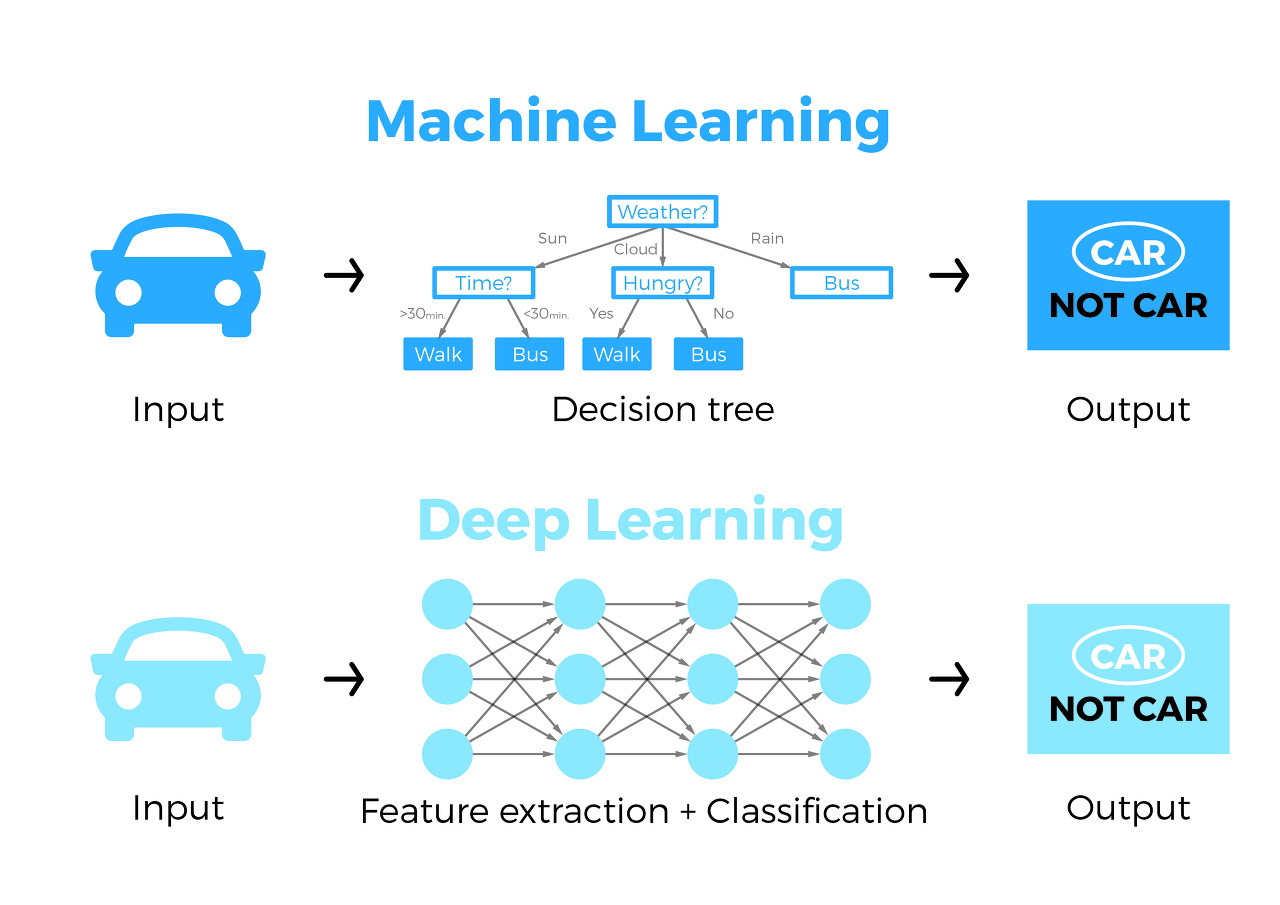
인공지능이 우리가 생각하는 많은 범위에서 컴퓨터가 지능이 있다라는 것을 뜻한다면, 머신러닝은 무엇일까요? 머신러닝은 우리가 생각하는 인공지능에 보다 가깝습니다. 컴퓨터가 데이터를 통해 학습하면서 지능을 갖춰 나가고 있기 때문이죠. 기존의 인공지능을 구현하기 위해서 수많은 패턴들을 미리 구현해놔야 했다면 머신러닝은 데이터를 학습하기 때문에 패턴을 만들 필요가 없습니다.

위 그림은 전통적인 프로그램과 머신러닝의 차이점을 보여주는데요. 기존의 프로그램은 우리가 룰을 정하고, 거기에 맞춰 개발자의 개입하에 프로그램을 완성합니다. 프로그램의 성능은 개발자의 프로그래밍에 상당히 많이 달려있어서 개발자가 똑똑하고 능숙할수록 때로는 머신러닝보다 뛰어난 프로그램이 나오기도 합니다.
머신러닝은 결과를 기반으로 데이터를 학습하여 진행하기 때문에 개발자의 개입이 없다고 볼 정도이고, 초기 데이터를 어떻게 만들것인지 어떤 머신러닝 알고리즘을 쓸 것인지 등을 토대로 튜닝을 하여 머신러닝 성능을 고도화 시킵니다. 물론 머신러닝 역시 능숙한 머신러닝 개발자 혹은 모델러가 참여하면 성능이 좋아지지만, 제일 필요한 것은 데이터이기 때문에 전자와 많이 다릅니다.
머신러닝의 대표적인 알고리즘으로 신경망(Neural Network), KNN, 결정트리(Decision Tree), 조건부 확률, 랜덤 포레스트(Random Forest) 등이 존재하며 우리가 흔히 접하는 통계도 머신러닝의 일종으로 포함시킬 수 있습니다. 통계라는 것도 결국 데이터를 학습하여 만들어진 결과이기 때문이죠.
딥러닝(Deep Learning)
딥러닝은 머신러닝의 알고리즘 중 하나인 신경망을 고도화해서 만들어진 개념입니다. 사실 많은 머신러닝 중 신경망은 인간의 지능을 모방한 알고리즘으로 컴퓨터에게 가장 이상적으로 지능을 부여할 수 있기 때문에 많은 연구가 진행되었지만 성능의 한계가 있었고 다른 머신러닝 알고리즘보다 특별히 장점이 있다 할 수 없을 수준이었습니다.
다른 알고리즘들은 성능이 유사하면서도 속도가 훨씬 빠르거나 결과에 대해서 해석이 가능하거나 인간이 이해하기 쉬운 형태가 있었지만, 신경망의 경우 튀는 데이터가 많았기 때문에 초반에 신경망으로 가다가 다른 알고리즘으로 전환하는 사례가 많았습니다.
그러다가 역사적인 일이 있었는데 바로 이미지 분류 대회에서 토론토대의 제프리 힌튼 교수가 이끄는 조직이 압도적인 성능으로 우승을 하였으며 해당 대회에서 신경망을 고도화한 것이 알려지면서 엄청나게 큰 이슈가 되었습니다. 해당 신경망은 기존의 신경망보다 훨씬 큰 레이어와 노드를 가졌기 때문에 딥러닝이라는 말이 붙어졌으며, 이후에 수많은 알고리즘 대회에서 수많은 딥러닝 알고리즘등이 등장하면서 대회를 모두 격파해 나갔습니다.

한국의 경우 2016년 이세돌이 딥마인드의 알파고에 지면서 붐이 났었는데요. 딥러닝의 본격적인 등장은 2012년 정도로 빅데이터의 패러다임 전환과 가상화라는 기술로 인해서 딥러닝의 날개를 달아주게 되었습니다.
이처럼 딥러닝이라는 것은 신경망의 분야중 매우 큰 모형을 가진 신경망을 뜻합니다. 문제는 초창기 딥러닝은 매우 큰 모형이다보니 딥러닝의 정의로 10개 이상의 레이어를 가진 신경망이라는 말들이 있었다가 2개의 히든 노드를 포함하는 4개 이상의 레이어까지 내려가다 우리가 흔히 생각하는 딥러닝 알고리즘 중 히든 노드가 없이 Input과 Output만 있는 모형도 있다보니 최근에는 신경망을 사용하는 것을 딥러닝이라고 부르기도 합니다.
이는 빅데이터의 용어 발전과 비슷한데요. 초창기의 빅데이터는 일반적인 시스템이 감당할 수 없는 데이터의 양을 뜻하였기 때문에 기본적으로 테라바이트가 넘었지만 최근에는 기가 단위라도 빅데이터라 하는 것과 같다고 보시면 됩니다.
인공지능, 머신러닝, 딥러닝 관계
결국 3개의 개념의 포함관계를 보면 아래의 그림과 같습니다.

딥러닝으로 만들어졌다라고 한다면 머신러닝으로 만들어졌다라고 할수도 있고, 인공지능이다 할 수 있습니다. 신경망 알고리즘이 아닌 다른 머신러닝 알고리즘으로 만들어졌다면 인공지능이다 할 수도 있지만, 딥러닝이라 말을 하면 안됩니다.
'Deep Learning > Tensorflow & Keras' 카테고리의 다른 글
| 케라스(Keras) 이해하기 (아키텍처, 역사) (0) | 2022.11.28 |
|---|---|
| 텐서플로(Tensorflow) 이해하기 (0) | 2022.09.23 |
| 딥러닝(Deep Learning)의 데이터 표현, 텐서(Tensor) (0) | 2022.09.20 |